[논문 리뷰] HiFi-GAN
![[논문 리뷰] HiFi-GAN](/assets/HiFiGAN/HiFiGAN_Fig1.png)
논문 리뷰
HiFi-GAN : Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Jungil Kong, Jaehyeon Kim, JaeKyoung Bae, Kakao Enterprise, 2020, NeurIPS ===============================================================
Abtract
HiFi-GAN 이란 음성합성 모델을 제안한 논문입니다. HiFi-GAN은 매우 효울적으로 빠르게 음성합성(Text-to-speech, TTS)을 할 수 있다고 하며, 음성 신호는 다양한 사인파로 구성되어 있어 오디오의 주기적은 패턴을 이용해 음성의 품질을 높였다고 합니다.
Introduction
보편적으로 사용되는 음성합성 모델은 대게 2가지 단계(Two-Stage)로 수행됩니다.
- 먼저 주어진 텍스트에서 STFT, Mel-spectrogram 과 같은 Acoustic Feature를 추출하는 단계
- (1.)에서 생성된 Acoustic Feature를 시간 도메인으로 바꾸어 주는 단계 (Vocoder)
HiFi-GAN (2.) 단계에 초점을 맞추어 높음 품질의 음성을 생성할 수 있는 Vocoder 모델입니다.
DNN 기술이 Vocoder 분야에 적용되면서 WaveNet 과 같은 Auto-regressive (AR) 기반의 Convolutional neural networks 가 매우 좋은 성능을 보였습니다. 하지만 이러한 AR 기반의 모델들은 한번의 Feed-Forward 연산에 1개의 sample 만 예측할 수 있기에 매운 많은 연상량이 필요합니다. 이러한 문제를 해결하고자 이후에는 Flow 기반의 모델, Parallel WaveNet, WaveGlow 등 많은 DNN 기반의 Vocoder 가 제안되었고 매우 빠른 연산도 가능하게 되었지만, 여전히 많은 Parameter 수가 필요했습니다.
Generative adversarial networks (GANs)를 이용한 음성합성 모델도 많이 제안되었습니다. 그 중에서도 MelGAN의 경우, Raw waveform에서 Multi-scale로 구간을 추출해 생성하여 좋은 음성품질을 생성하고 CPU에서도 연산이 가능할 정도로 빠르게 생성할 수 있게 되었습니다. 이 외에도 GAN-TTS 와 같은 GANs 기법을 활용하여 시간 도메인의 Raw Waveform을 빠른 속도로 생성할 수 있는 방법들이 제안되었지만, AR 혹은 flow- 기반의 모델들보다 생성된 오디오의 품질이 좋지 않았습니다. 위의 GANs 기반의 모델들은 모두 Multi-resolutional 한 Acoustic feature를 이용하고나 Multi-resolutional 하게 Waveform을 생성한 것 같습니다.
HiFi-GAN 은 GANs 기법을 통해 학습되지만 AR 과 flow- 기반의 모델들보다 더 높은 품질의 Raw waveform을 생성할 수 있다고 저자들은 말합니다. 1개의 Generator와 2개의 Discriminator 를 사용하는 데 각 Discriminator는 특정 주기의 raw waveform을 입력으로 받는 구조를 가집니다.
Methods
Model Architecture
Generator
HiFi-GAN은 Mel-Spectrogram 을 입력으로 받습니다. n_mels : 80개 위의 그림은 HiFi-GAN 의 Generator를 설명하는 그림입니다. 전체적인 구조는 크게 Transposed Convolutional layers 와 Multi Receptive Field Fusion layers (MRF) 로 구성되어 있습니다. 여기서 MRF layers 본 논문의 저자가 디자인한 layer 로 추후에 말씀드리겠습니다.
입력 데이터인 주파수 도메인의 한 개의 frame 은 시간 도메인(Raw waveform)에서 window size에 해당하기에 Transposed layer 를 통해 upsampling 합니다. 그리고 MRF 는 ResBlock 구조를 가집니다. 그리고 각 ResBlock 은 Dilated convolutional layers 로 구성되이 있습니다. 위 그림에서 $k$ 는 Kerenl size, $h$ 는 hidden dimension 그리고 $D$는 dilation rate을 뜻하는 데요. $k$와 $D$를 각 Resblock 마다 다르게 주어 각 Block이 서로 다른 Receptive Field를 가지고 연산을 수행하게 된다고 합니다. 그리고 이 과정을 설정한 window size 와 hop length에 따라 $k_u$ 번 반복하여 block 쌓아 모델을 구성했다고 합니다.
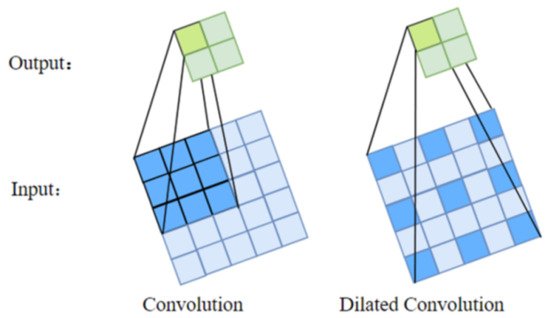
Dilated Convolution 에 대해 간략히 소개해드리자면, 일반적인 Convolutional layer 와 Dilated Convolution 의 차이는 위의 사진과 같습니다. 3x3 크기의 kernel size를 사용했을 때, Dilated Convolutional layer 는 이전 feature map 에서 설정한 Dilated rate 에 따라 각 pixel 을 띄어서 연산을 수행합니다. 이에 따라서, 같은 수의 parameter 로 더 넓은 크기의 Receptive field 를 가져갈 수 있습니다.
Discriminator
Raw Waveform에서 각 샘플은 인근의 다른 샘플에 의존적입니다. 예를 들어, 한 음절을 소리내어 발음하는데 100ms 가 걸린다면, 2,200 개의 샘플(sample rate = 22kHz) 에 상관관계를 가질 것 입니다. 이러한 문제점을 해결하고자 MelGAN 에서는 Gernerator 와 Discriminator 가 큰 Receptive field 를 가져감으로써 해결하고자 접근했었습니다. 반면, HiFi-GAN의 저자들은 Raw waveform 이 각 주기별로 다양한 사인파로 구성되어 있다는 점에 착안하여 접근했다고 합니다. 최종적으로 HiFi-GAN 은 MelGAN에서 제안한 Discriminator 와 본 논문에서 제안한 Discriminator 를 같이 사용함으로써 좋은 품질의 Waveform 을 생성할 수 있었다고 합니다.
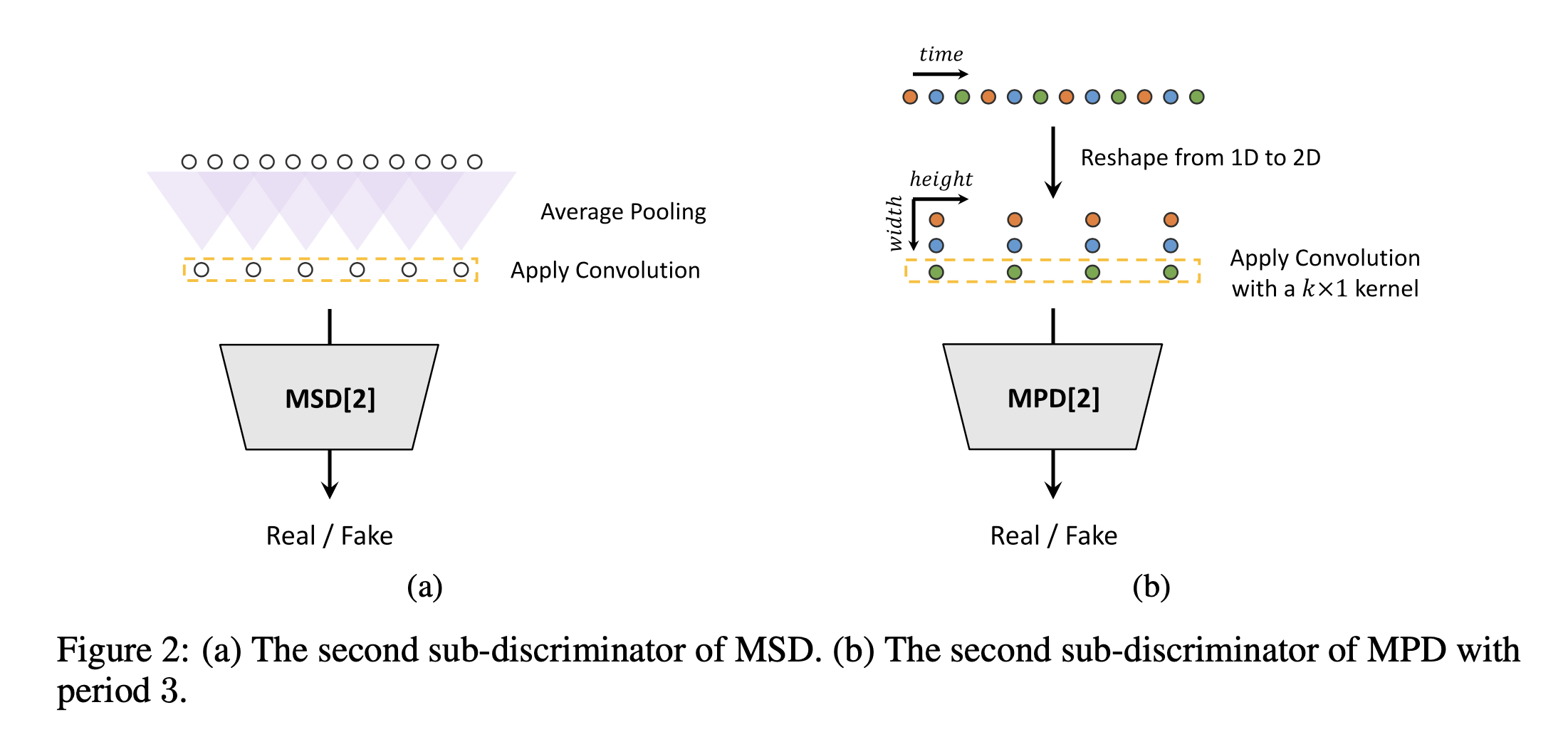
Multi-Period Discriminaotr (MPD)
먼저 HiFi-GAN의 저자들은 Multi-period discriminator(MPD)를 본 논문에서 제안했습니다. MPD 는 여러개의 sub-discriminator의 조합으로 서로 다른 주기 $p$로 Waveform 을 나누어서 1D 형태인 Waveform 데이터를 2D 형태로 바꾸어 연산합니다. 저자들은 중복을 최대한 피하기 위하여 주기$p$를 [2, 3, 5, 7, 11] 로 설정했습니다. 각 주기가 소수로 구성되어 있음을 알 수 있습니다. 그리고 각 샘플링한 데이터를 $T/p$ 형태로 2D 형식으로 바꾸어주어 입력으로 활용합니다. 이해를 돕기 위하여 예시로 설명 드리겠습니다. 제가 제대로 이해했다면요. 위의 그럼 Figure 2. 가 MPD의 두번째 Sub-discriminator, 즉 $p == 3$인 경우를 나타냅니다. $p == 3$ 이므로, 3 주기로 sampling 하여 [0, 3, 6, …], [1, 4, 7, …], [2, 5, 8, …] 식으로 3개의 층으로 분리하여 1D 의 데이터를 2D 형태로 변환합니다. 2D 형태로 바꾸어 줌으로써 모든 time step의 샘플에 대해 gradient를 전달할 수 있다고 합니다. 그리고 각 주기로 나누어진 샘플을 독립적으로 계산하기 위해 kernel size 의 너비 축을 1로 고정하여 연산합니다. 추가적으로 Leaky ReLU activation function 과 weight normalization을 모든 convolution layers 에 적용했다고 합니다.
Multi-Scale Discriminator (MSD)
Multi-scale discriminator 는 MelGAN 에서 제안된 Discriminator 입니다. MPD 는 주기에 따라서 연속적인 sample 을 사용하지 않습니다. 따라서, HiFi-GAN 에서는 MSD를 함께 사용했습니다. MSD는 각기다른 Scale 을 입력으로 가지는 sub-discriminators 로 이루어졌습니다. Raw audio, x2 averaged-pooled audio 그리고 x4 averaged-pooled audio 로 average pooling 을 이용해 audio 의 scale 을 조절합니다. 그리고 각 sub-discriminator는 Leaky ReLU를 사용하고 동일한 모델 구조를 가지지만, stride와 layers의 수를 추가함으로써 그 크기를 조절합니다. Weight normalization 은 raw audio를 제외한 다른 2개의 sub-discriminator에만 적용했다고합니다. MSD는 MPD와 다르게 연속적인 샘플을 활용하기 때문에 smoothing 하는 효과를 가진다고 합니다.
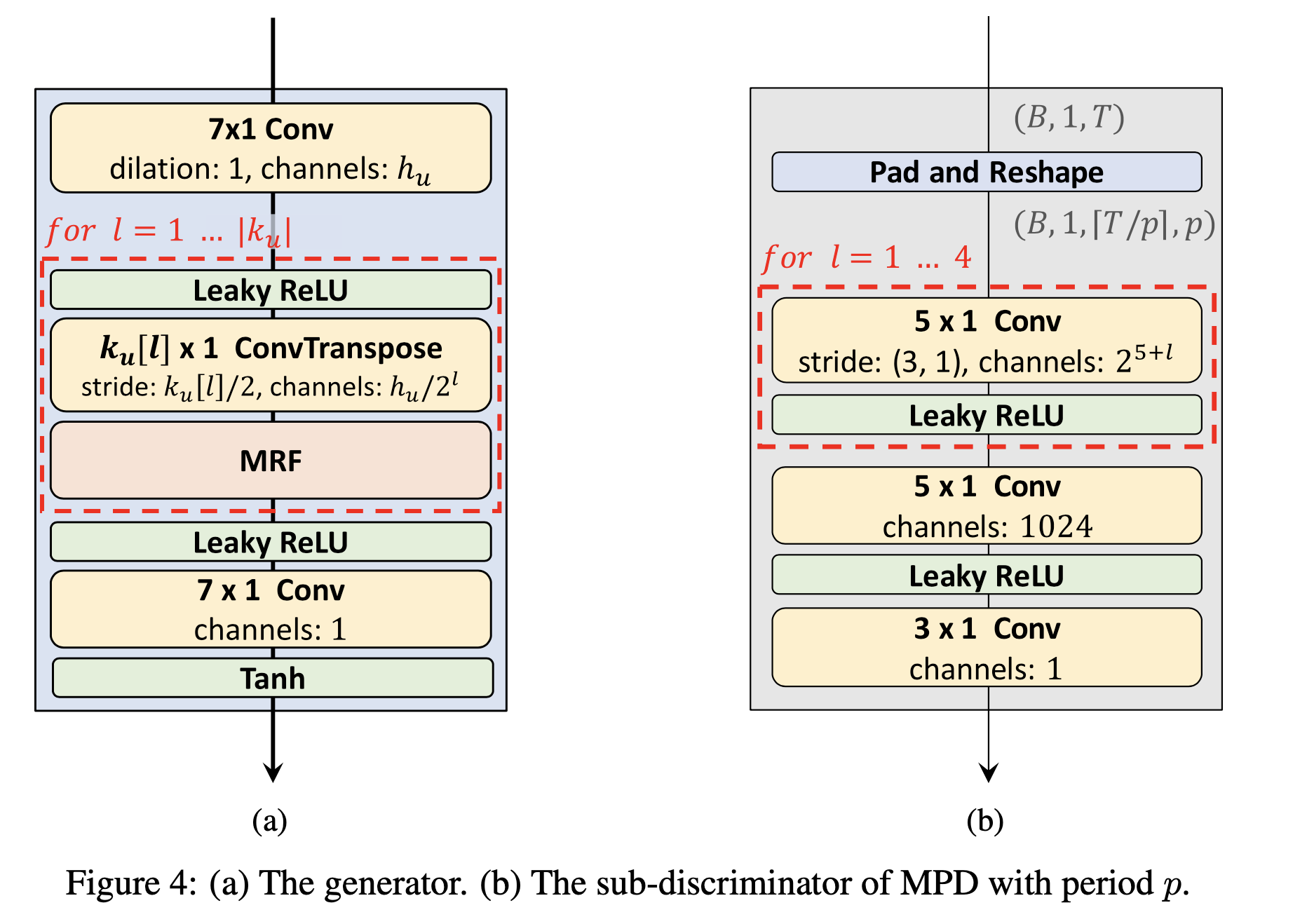
여기까지 HiFi-GAN의 Generator 와 Discriminator에 대한 설명이었습니다. 위의 그림은 HiFi-GAN에서 제시한 Generator 와 MPD 의 구조를 나타낸 그림입니다.
Loss Functions
HiFi-GAN 은 총 3가지 종류의 손실함수, GAN Loss, Mel-spectrogram Loss 그리고 Feature Matching Loss를 사용하여 합습됩니다.
GAN-Loss
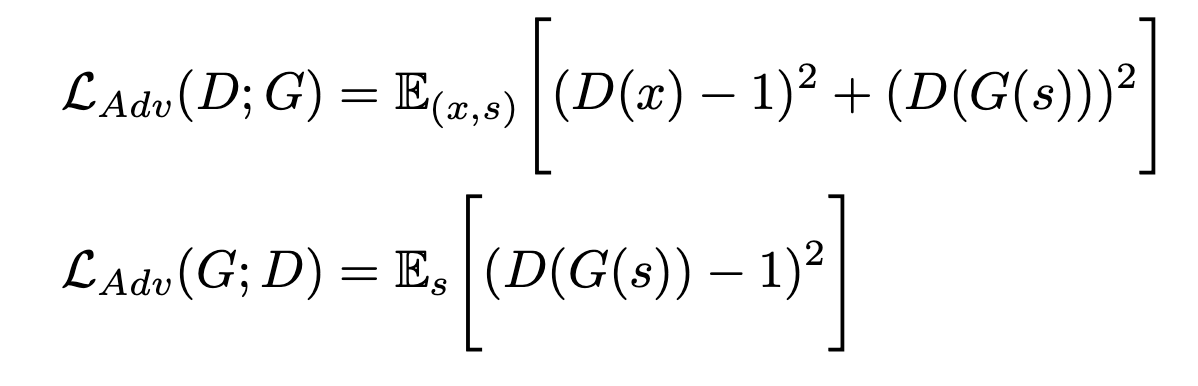
HiFi-GAN 은 2가지 Discriminator 를 사용합니다. 일반적으로 Binary cross entropy 를 사용하는 GANs 대신 Leat mean square를 사용하는 LS-GAN 방식을 사용했습니다.
Mel-Spectrogram Loss

HiFi-GAN 은 Mel-Spectrogram Loss 를 추가하여 학습 효율을 높였다고 합니다. mel-spectrogram loss 는 생성된 audio와 ground truth audio 데이터를 각각 Mel-Spectrogram 으로 변환한 뒤, 두 mel-spectrogram 간에 L1 loss를 통해 계산한다고 합니다.
Feature Matching Loss
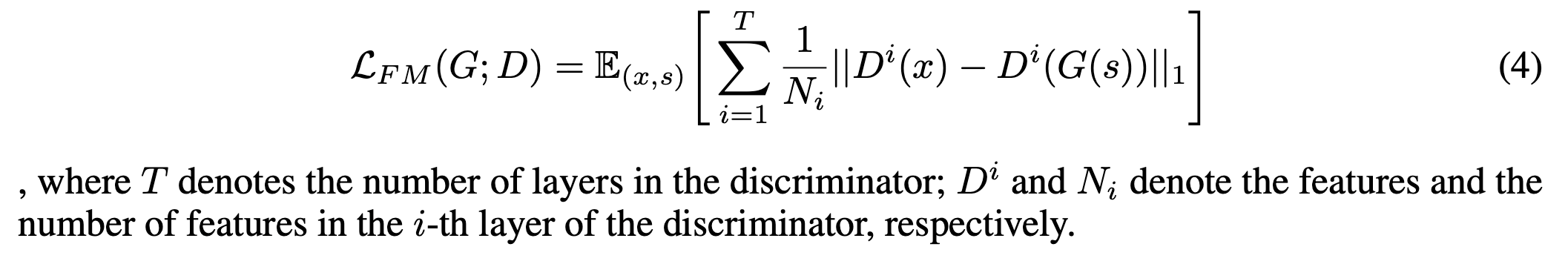
마지막으로 Feature Mathching Loss 를 사용했습니다. Feature map loss 는 Discriminator 에서 생성되는 Feature map 을 활용합니다. 생성된 Waveform 과 Ground truth waveform 을 Discriminator를 통과시키면, 각 layer 마다 feature map 을 출력하는데요. 이때 각 생성된 waveform 에 대한 feature map 과 ground truth waveform 에 대한 feature map 간의 유사도를 L1 Loss 로 측정하여 계산합니다.
최종 사용되는 Loss 함수는 다음과 같습니다. 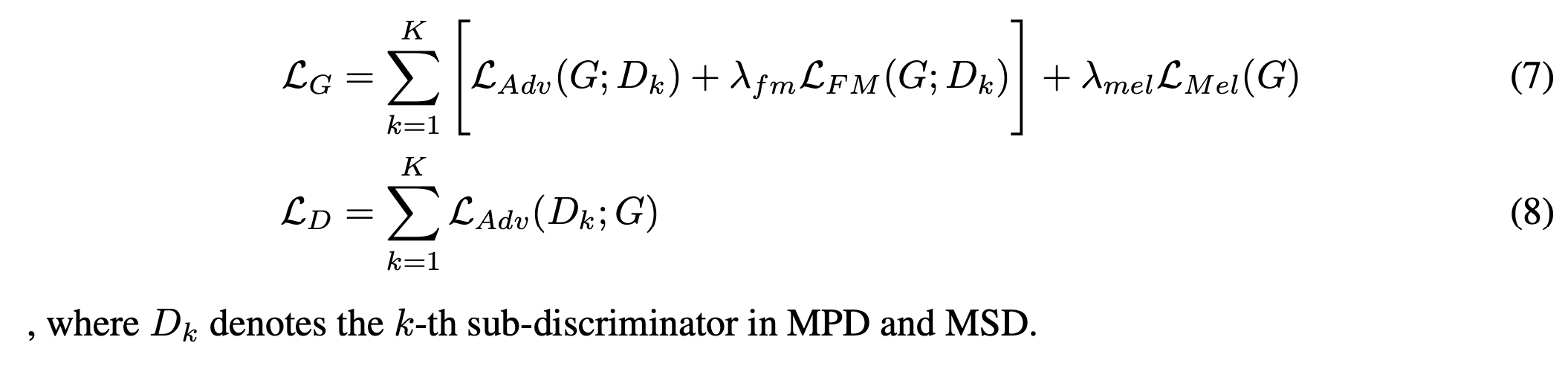
Experiments & Result
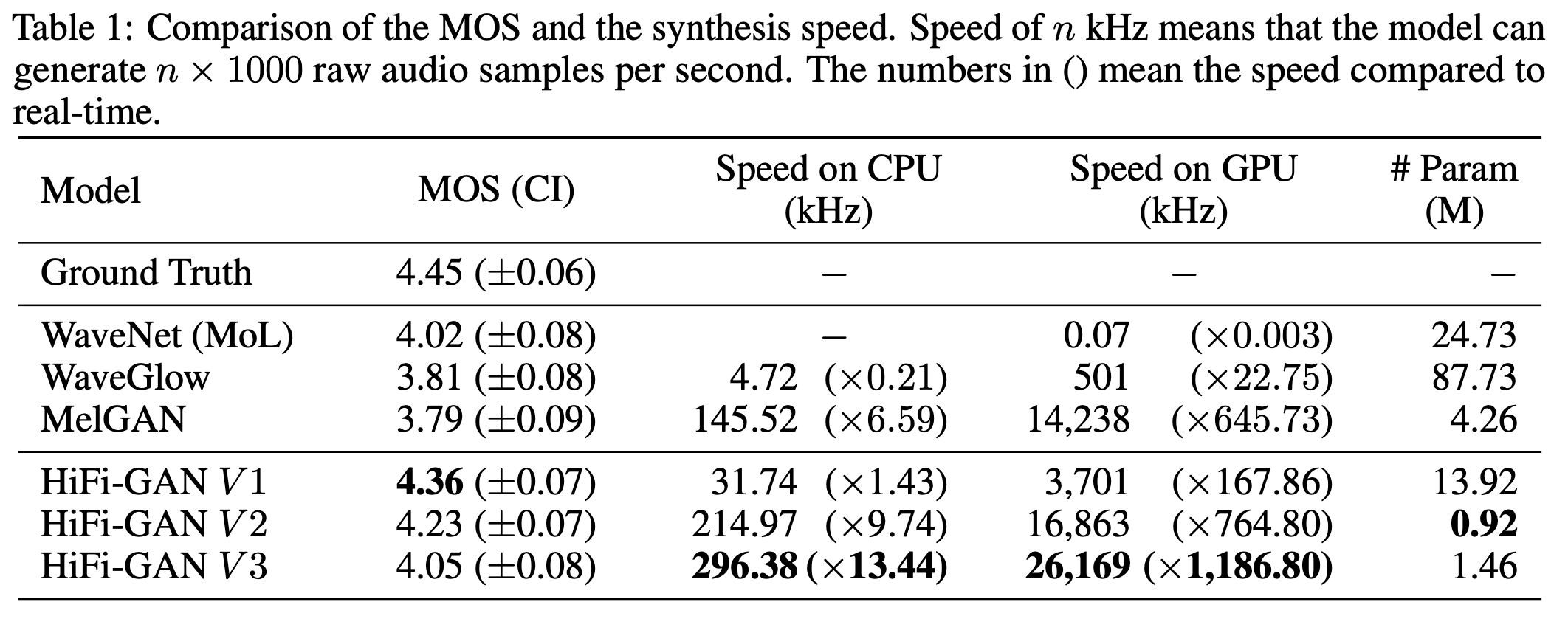
위의 표는 이전까지 널리 쓰인 Vocoder 모델인 WaveNet, WaveGlow 그리고 MelGAN과의 성능비교입니다. 평가함수로는 사람의 의견을 종합하여 점수를 메기는 Mean opinion score (MOS)를 사용했습니다. 그리고 LJSpeech dataset 을 이용해 각 모델을 학습시켰습니다.
결과를 보면, HiFi-GAN V3 의 경우, 다른 모델들보다 훨씬 빠른 속도를 보임에도 WaveNet, WaveGlow 그리고 MelGAN과 비슷한 점수를 획득한 것이 인상적입니다. HiFi-GAN V1 의 경우에도 WaveNet과 WaveGlow 보다 훨씬 적은 parameter 수로 Ground Truth 와 거의 동일한 점수를 획득하여 자연스러운 audio를 생성해냈다는 사실이 놀랍습니다.
공식 Github & demo URL
아래의 URL 주소를 통해 공식 코드와 데모 오디오 데이터를 확인하실 수 있습니다.
Github : https://github.com/jik876/hifi-gan
Demo : https://jik876.github.io/hifi-gan-demo/
Reference
HiFi-GAN 논문 : https://arxiv.org/abs/2010.05646
Dilated Conv image : https://www.mdpi.com/2072-666X/12/5/545