[논문 리뷰] Tacotron 2
![[논문 리뷰] Tacotron 2](/assets/Tacotron2/Tacotron2_arch.png)
논문 리뷰
NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS
Jonathan Shen, 2018, Google
===============================================================
Abtract
본 논문에서는 Tacotron2 란 음성합성 (Text-to-speech, TTS) 모델을 제안합니다. Tacotron2 는 주어진 문장을 토대로 Acoustic feature를 생성하는 모델입니다. 생성한 Acoustic feature 를 다시 시간 도메인 (Waveform) 데이터로 변환할 때는 WaveNet 을 Vocoder 로 활용해서 진행했하여 우수한 품질의 audio 데이터를 생성해 낼 수 있었다고 합니다.
Introduction
음성합성 모델은 대게 2가지 단계를 거칩니다.
- 먼저 주어진 텍스트에서 STFT, Mel-spectrogram 과 같은 Acoustic Feature를 추출하는 단계
- (1.)에서 생성된 Acoustic Feature를 시간 도메인으로 바꾸어 주는 단계 (Vocoder)
여기서 Tacotron2 는 1번에 해당하여, 주어진 문장을 토대로 Acoustic feature를 생성하는 모델입니다.
이전에는 통계적 기법을 통해 TTS 를 수행했습니다. 각 발음마다 작은 단위로 녹음한 Waveform 을 주어진 문장에 맞게 연결하여 생성했습니다. 하지만 이러한 전통적인 방법은 각 발음마다 끊어져서 들리는 단점이 있고 충분히 자연스럽지 못 했습니다. 이후, Deep Neural Network (DNN) 이 적용된 TTS 모델이 Tacotron 이 제안되어 많은 성능 향상을 보였습니다. Tacotron 은 기존의 음성합성 pipeline 에서 acoustic feature 를 DNN으로 성공적으로 대체했는데요. 이렇게 생성한 Acoustic feature 를 Griffin-Lim 이라는 알고리즘 기반에 Vocoder 를 통해 다시 시간 도메인으로 변환하는 방법을 제시했습니다.
반면 Tacotron 2는 음성합성 pipeline을 모두 DNN 모델로 대체했습니다. Tacotron 2 는 주어진 문장을 DNN 모델을 통해 Acoustic feature 를 생성하고, 이를 WaveNet 이라는 DNN기반의 Vocoder 를 통해 Waveform 으로 변환하는 새로운 pipeline 을 제시했습니다.
Model Architecture
Tacotron 2 의 전체적인 모델 구조는 위의 그림과 같습니다. Acoustic feature 로는 Mel-Spectrogram 을 선택했다고 합니다. Mel-spectrogram 은 사람이 인지하는 청각 신호를 모형화한 feature 로 저주파 부분을 강조하고 고주파 부분을 약하게 표현합니다. 사람의 음성 신호는 대부분 저주파 부근에 밀집해있어 Mel-Spectrogram 은 사람의 음성신호를 분석하는 데 많은 이점이 있는 feature 입니다. Tacotron 2 에서는 short-time Fourier transform (STFT)을 50 ms frame size, 12.5 ms frame hop 그리고 a Hann window function 을 사용해 연산을 수행하고 Mel-Spectrogram을 추출했습니다. 그리고 80 mel filterbanks 를 사용했습니다.
Tacotron 2
Tacotron 2 는 Encoder 와 Decoder 로 구성되어 있습니다. Encoder 는 주어진 문장으로 부터 hidden feature representation 을 추출하는 역할을 수행합니다. 먼저 문장을 Vector 형태로 변환하기 위해 Character Embedding (N-grams)을 수행합니다. Convolutional layers 와 Bidirectional LSTM layer 로 구성되어 있는 걸 확인할 수 있고, 각 frame 별로 512 hidden nodes 를 출력합니다. 여기서 Encoder 의 출력값은 Decoder의 각 output step 마다 필요한 fixed-length context vector를 전달해주는 Location Sensitive Attention 을 사용합니다. 이러한 과정을 통해서 Decoder가 중복되는 갑을 출력하거나 혹은 특정 구간을 건너뛰는 문제를 완화할 수 있다고 합니다.
그리고 Decoder 는 한 step 마다 Mel-Spectrogram 의 한 frame 을 생성하는 autoregressive RNN으로 구성되어 있습니다. 먼저 전 출력 값(t-1)은 그림의 좌측에 보이는 Pre-Net을 통과하게 됩니다. 저자들은 이 Pre-Net 이 attention 을 학습하는 데 있어, 필요한 특징을 학습한다는 걸을 알아냈다고 합니다. 그리고 이 Pre-net 출력 값과 attention context vector 와 concatanation 연산을 통해 합하여 2개의 uni-directional LSTM layers 를 통과시키게 됩니다. 그리고 이 2개의 LSTM layers 를 통과한 출력값과 attention context vector를 conatenation 하여 우측에 보이는 linear transform 을 거치면 1개의 Mel-Spectrogram frame 을 생성하게 됩니다. 그리고 이 frame을 좌측 상단의 Post-Net을 통과시키는 데, 이 과정을 통해서 더 높은 품질의 Mel-Spectrogram 을 생성할 수 있다고 합니다. 이렇게 생성된 Mel-Spectrogram 과 Ground Truth Mel-Spectrogram 과 Mean-squared error (MSE)를 목적 함수로 사용해 최소화 시키며 학습을 하게 됩니다. (log-likelihood loss 를 사용해 그 데이터 분포를 이용해 학습시키고자 시도를 해보았지만, 학습 시키기 매우 어려웠다고 합니다.) 또, 병렬적으로 중앙 부분의 LSTM 출력 값을 통해 Linear transform 을 수행하여 얻은 값으로 Stop Token을 예측하도록 설계했습니다. 이때 값이 0.5 임계 값을 초과하면 더이상 frame을 생성하는 것을 멈추도록 설정하고, 이를 통해서 문장 길이에 따라 고정된 길이가 아닌 동적으로 Mel-Spectrogram의 frame 수를 결정합니다.
Vocoder - modified WaveNet
사실 Tacotron 2 논문에서 주된 Conribution 은 Encoder, 즉 주어진 Text 를 입력으로 받아 Mel-spectrogram 을 추출하는 데 있습니다. 그래서 Vocoder 로 다른 모델을 사용해도 무방합니다. NVIDIA 에서 Tacotron 2 의 사전학습된 모델과 Pytorch 기반의 구현 코드 를 제공하는 데, 여기서는 WaveNet이 아닌 WaveGlow 를 Vocoder 를 사용하기도 했습니다. 하지만 논문에서는 WaveNet 을 수정한 버전을 제안했습니다.
기존의 WaveNet 과 같이 30개의 Dilated convolution layers 를 사용했습니다. 다만, 12.5 ms hop length 를 맞추기 위해 WaveNet 과 다르게 2 개의 upsampling layers 가 사용되었다고 합니다. 그리고, Softmax 를 이용해 분류하는 것이 아닌, PixelCNN++ 와 Parallel WaveNet에 따르고, 10 compent mixture of logistic disctributions (MoL)을 사용해 24 kHz 의 16 bit sample을 생성했습니다.
Experiments
학습시킬 때는, Encoder 와 Vocoder 각각 독립적으로 학습시켰습니다. 데이터 셋으로는 1명의 여성이 24.6 시간동안 녹음한 US English dataset을 사용했다고 합니다. 추가적으로 추론시에는 Ground Truth 데이터가 존재하지 않습니다. 따라서, WaveNet 등 Auto-regressive 구조가 필요한 부분은 이전 스텝에 대한 출력 값을 아웃풋으로 활용했다고 합니다.
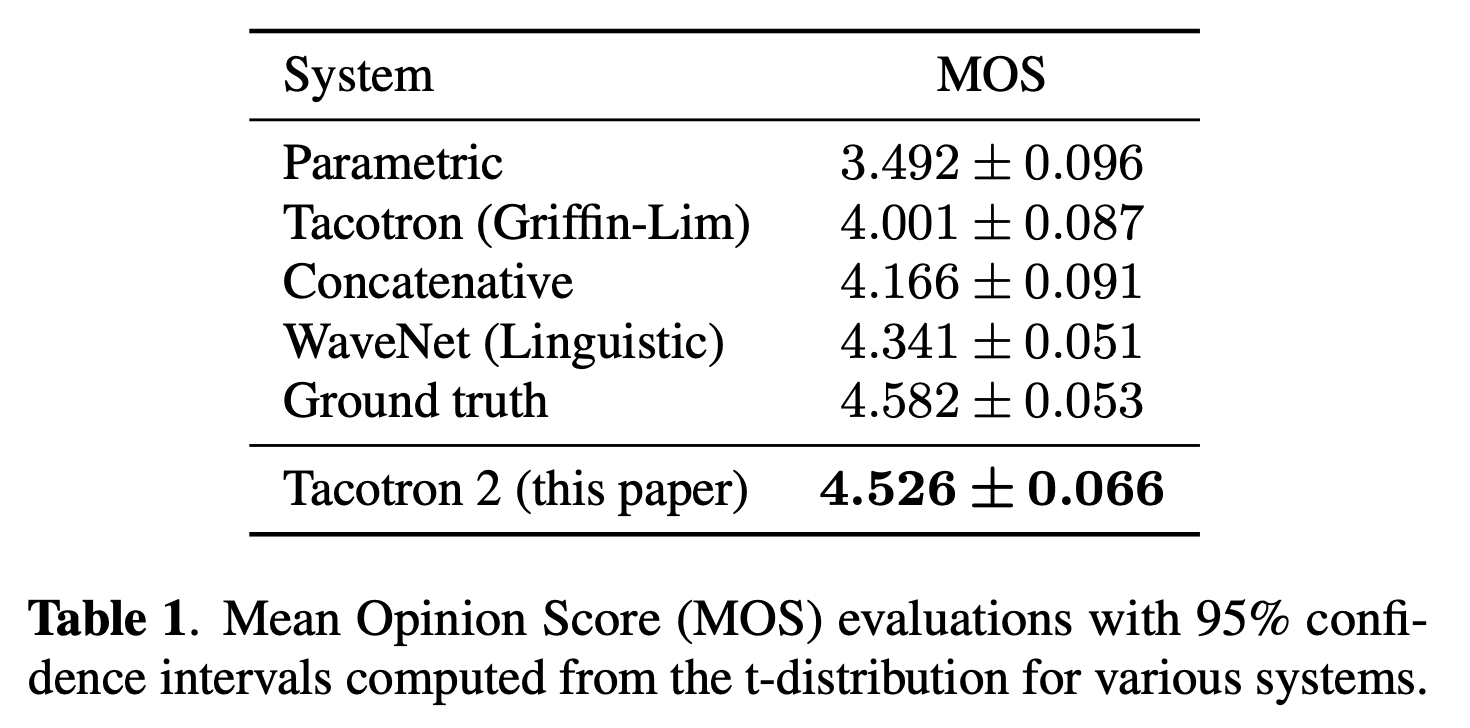
위의 테이블은 이전 버전인 Tacotron 과의 MOS 점수를 비교한 테이블입니다. 실제 사람이 녹음한 데이터인 Ground Truth 가 4.58 점을 받았는데, Tacotron 2는 그와 비슷한 수치인 4.526 점을 받았습니다. 반면 이전 버전인 Tacotron 은 4 점을 겨우 넘겼네요.
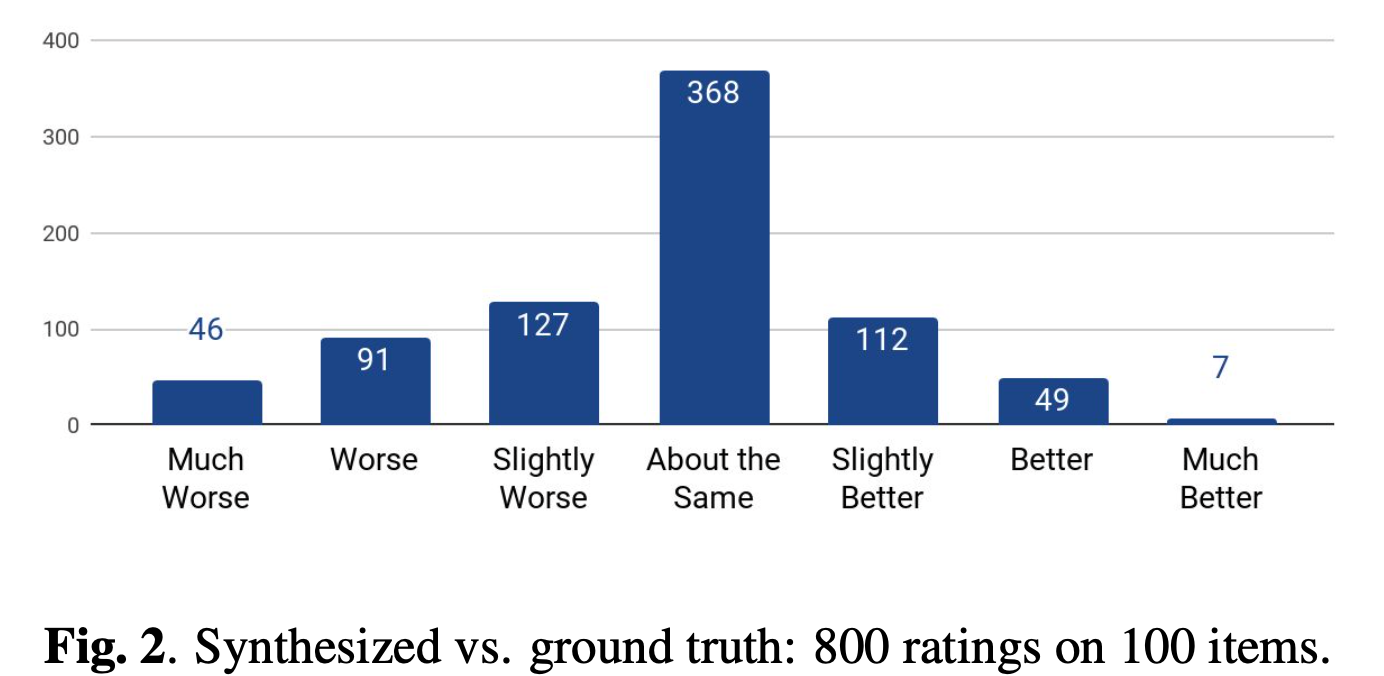
Tacotron 2 가 생성해 낸 음성과 실제 녹음본과의 차이에 대해 점수를 메긴 실험 결과입니다. 비슷하다는 의견이 가장 많았고, 오히려 더 자연스럽다라고 답한 결과도 많습니다. 이 결과를 토대로 Tacotron 2 가 얼마나 자연스러운 음성을 생성하는 지를 알 수 있습니다.

저자들은 Mel-Spectrom 으로 학습시키는 것이 과연 더 좋냐 그리고 WaveNet 을 사용하는 것이 좋냐라는 의문점을 해결하기 위한 실험도 실시했습니다. 위의 Linear 라고 적힌 부분은 Mel-Spectrogram 을 추출한 것이 아니고 Griffin-Lim 알고리즘을 사용할 수 있도록 linear-frequency feature 를 바로 추출하도록 학습시킨 모델입니다. 그리고 G-L은 Griffin-Lim 을 사용했는 지에 대한 여부를 나타냅니다. 표에서 알 수 있듯이, Mel-Spectrogram 과 WaveNet 조합이 가장 좋은 결과를 보입니다.
Conclusion
Tacotron 2는 문장 정보에서 음성 생성까지 모든 과정을 Deep Neural Network 로 대체하여 놀라운 결과를 보여주었습니다. 이를 이용하면 음성합성에 대한 전문적인 지식이 없더라도 TTS 시스템을 구현할 수 있게 되었습니다.
의문점 혹은 의견
사실 저는 본 논문을 읽고 몇가지 의문점이 들기도 했습니다. 다음에 기회가 된다면 직접 구현을 해서 의문점을 해결해봐야 겠습니다. 제가 가진 의문점은 다음과 같습니다.
MSE Loss 함수의 사용 : 같은 문장이라고 사람마다 다르게 발음할 수 있습니다. 더군다나 같은 문장을 같은 사람이 읽는다고 하더라도 매번 다르게 읽을 수 있습니다. 그럼에도 MSE Loss 만을 이용해서 학습시켜서 좋은 성능을 보였다는 사실이 놀랍습니다. 본 논문에서는 1명의 화자만 녹음한 데이터셋을 사용했습니다. 그래서 MSE Loss 함수로도 가능한 건지, Multi-Speaker 데이터를 이용하면 성능이 어떻게 나오는 지 궁금하네요.
Stop Token : Stop Token 의 경우는 어떤 목적함수로 학습시키는 지 논문에 명시되어 있지 않았습니다. Binary cross entorpy loss 를 통해 함께 학습시키는 지, 혹은 해당 부분에 대한 Loss 는 고려하지 않고 Autogressive 의 특성을 이용해 함께 학습되는 지 추후에 확인해봐야 겠습니다.
References
Tacotron 2 논문 : https://arxiv.org/abs/1712.05884
Tacotron 2 Demo : https://google.github.io/tacotron/publications/tacotron2/
NVIDIA 구현 코드 (Pytorch) : https://github.com/NVIDIA/tacotron2