[논문 리뷰] LVCNetcopo
![[논문 리뷰] LVCNetcopo](/assets/LVCNet/LVC.png)
논문 리뷰
LVCNET: EFFICIENT CONDITION-DEPENDENT MODELING NETWORK FOR WAVEFORM GENERATION Zhen Zeng, ICASSP, 2021
================================================================= UnivNet 을 먼저 리뷰하고자 했지만, UnivNet 을 이해하기 위해선 LVCNet 을 먼저 이해해야 할거 같아 LVCNet 을 먼저 리뷰하게 되었습니다.
Abstract
본 논문에서는 LVCNet 이라는 새로운 Vocoder 모델을 제안했습니다. Location-variable convolution 이라는 새로운 형식의 convolution 을 제안했는데요. Waveform 의 각 시점마다 서로 다른 Kernel 을 적용할 수 있는 Convolution 입니다. 해당 Convolution 의 효과를 입증하기 위해 Parallel WaveGAN 에 적용해서 실험을 진행했는데, 추론속도가 성능 저하 없이 빨라지는 것을 확인했다고 합니다.
Introduction
DNN 이 음성합성 분야에 적용되고 초기에는 WaveNet 등 Auto-regressive 방식으로 접근했습니다. 높은 품질의 오디오를 생성할 수 있지만, 추론 속도가 매우 느리다는 단점이 있습니다. 이후에 이러한 문제를 해결하고자 WaveGlow, WaveFlow 등의 flow-based generation 모델이 제안되기도 했습니다. Gernerative adversarial networks (GANs) 도 적용되어 MelGAN, Parallel WaveGAN 등이 제안되었는데, 이러한 GANs 기반의 모델들은 이전에 제안되었던 방법들보다 훨씬 빠른 추론속도를 보였습니다. 이러한 모델들의 공통점은 Wavenet을 기반으로 두어, dilated causal network 를 이용해 long-term dependencies 를 계산하고, Mel-Spectrogram 을 입력으로 주어 gated input unit 을 위한 local condition 으로 활용한다는 점입니다. 그렇기 때문에 wavenet-like networks 는 time-dependent feature 를 효과적으로 추출하기 위해 많은 convolution layers 가 필요하게 됩니다.
본 논문에서는 Time-dependency feature 를 더 효과적으로 추출할 수 있는 Location-variable convolution (LVC) 를 제안했습니다. LVC 는 Waveform 에서 각 간격마다 다른 kernel의 coefficient 를 사용할 수 있으며, Mel-Spectrogram 을 조건으로 활용하여 coefficient 를 구하게 됩니다. 저자들은 LVC 를 기반으로 LVCNet 모델 구조를 제안했고, 이를 Parallel WaveGAN 에 적용하여 더 효과적은 Vocoder 를 학습시킬 수 있었다고 합니다. 따라서 본 논문의 contribution 은 다음과 같이 세가지로 정리할 수 있습니다.
- location-variable convolution 이라는 새로운 Convolution 방법을 제안했습니다.
- LVC 를 기반으로 LVCNet 이라는 모델 구조를 설계했으며, Parallel WaveGAN에 적용했습니다.
- Waveform을 생성하는 데 있어, LVC 의 효용성을 입증했습니다.
Proposed Method
Location-Variable Convolution
기존의 linear prediction vocoder의 경우, Auto-regressive 방법을 이용하기 위해, Acoustic feature 로 계산된 coefficient 를 이용하여 all-pole linear filter 를 생성하여 waveform을 생성했습니다. 이는 Wavenet Vocoder 와 매우 유사하지만, Wavnet 은 모든 frame에 대해 고정된 coefficient 를 사용합니다. 저자들은 위 사실을 활용하여, 각 waveform 구간 마다 그에 맞는 coefficient 를 구하고 적용시킬 수 있는 convolution 연산 방법을 생성하고자 했다고 합니다.
위의 사진은 본 논문에서 제안하는 LVC 의 구조를 나타냅니다. 위의 그림에서 알 수 있듯이, Kernel Predictor 부분이 각 구간마다 다른 coefficient 를 출력하고, 이를 활용해 각 구간마다 다른 가중치 값을 가지고 convolution 연산을 수행하게 됩니다. 여기서 local-condition \(h\) 는 그 시간 위치에 따른 acoustic feature, 즉 Mel-spectrogram 이 활용됩니다. 추가적으로 WaveNet 과 비슷하게 gated activation unit 을 적용했다고 합니다. 위의 내용을 수학적으로 정리하면 아래와 같습니다.

여기서 Gated activation unit 은 식 (2) 에 해당 되는데, $Tanh$ 연산과 $sigmoid$ 가 함께 수행되는 부분입니다. $sigmoid$ 연산에 의해서 0 인 부분은 비활성화되고 다른 부분은 활성화되는 성질을 가지기 때문에 gated activation unit 이란 이름을 가지게 되었습니다.
다시 되돌아와서, 위에 설명드린 바와 같이 LVC 는 각 구간마다 local condition 에 의해 waveform을 생성하는 데 있어, 서로 다른 coefficient 가 사용됩니다. 이 덕분에 기존의 convolution 연산보다 long-term dependency 를 활용할 수 있다고 주장합니다.
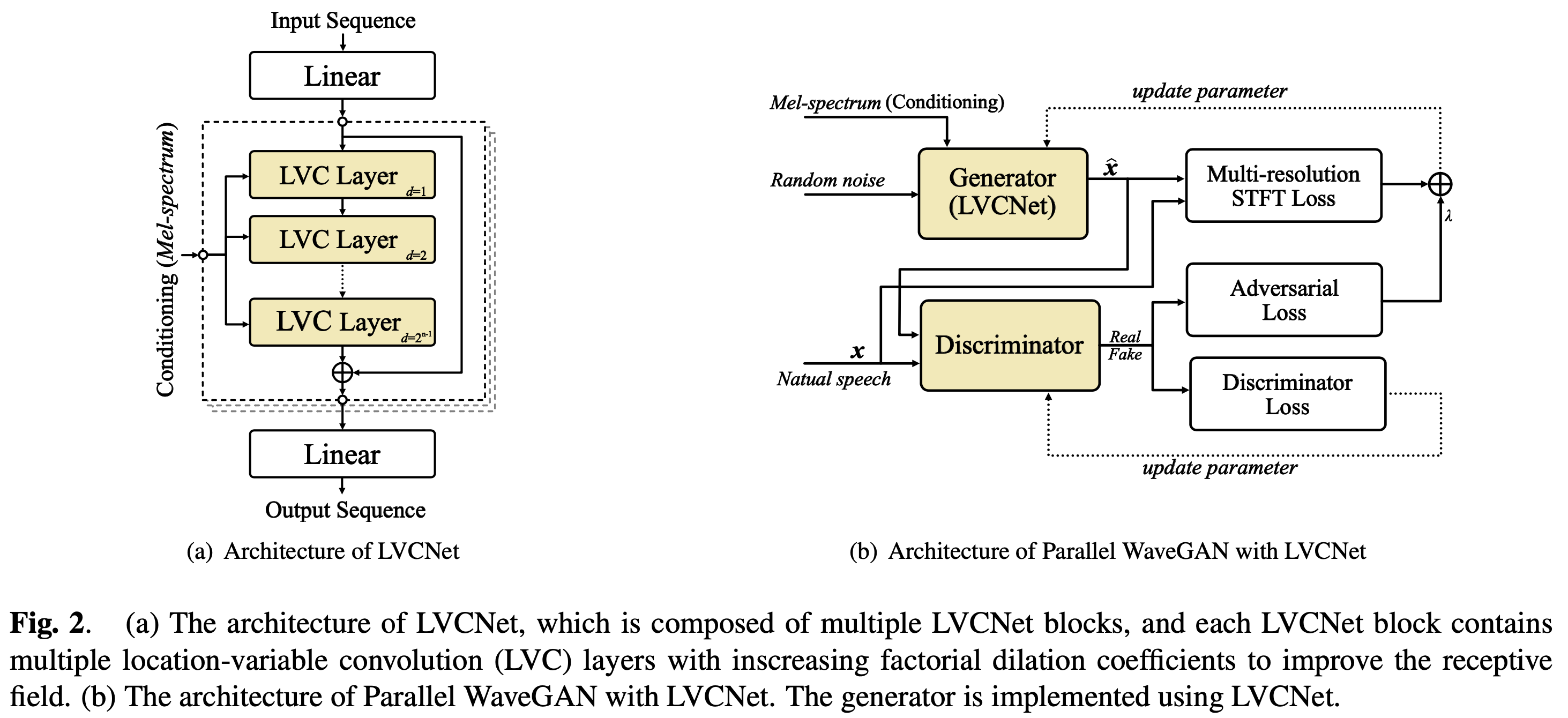
LVCNet
LVCNet 은 이름에서 알 수 있듯이, LVC layers 로 구성된 LVCNet Block 으로 이루어진 모델입니다. 각 LVCNet Block 은 여러개의 LVC layers 구성되어 있으며 factorial dilation coefficient 를 증가시키는 데, 이를 통해 더 넓은 Receptive field 를 사용할 수 있다고 합니다. 각 LVCNet block 들은 conditioning sequence, 즉 acoustic feature도 각 block 마다 입력으로 주어집니다. 그리고 마지막에 channel conversion 효과를 주기 위해 Linear layer 가 추가되었다고 하네요.
Parallel WaveGAN with LVCNet
LVCNet 만 아니라, LVC 의 효용성을 확인하기 위해 Parallel WaveGAN 에 적용하여 그 성능 차이를 확인했습니다. 위의 그림에서 오른쪽 그림이 이를 나타냅니다. Generator 가 LVCNet 으로 대체되어 활용된 것을 확인 할 수 있습니다.
Experiment & Result
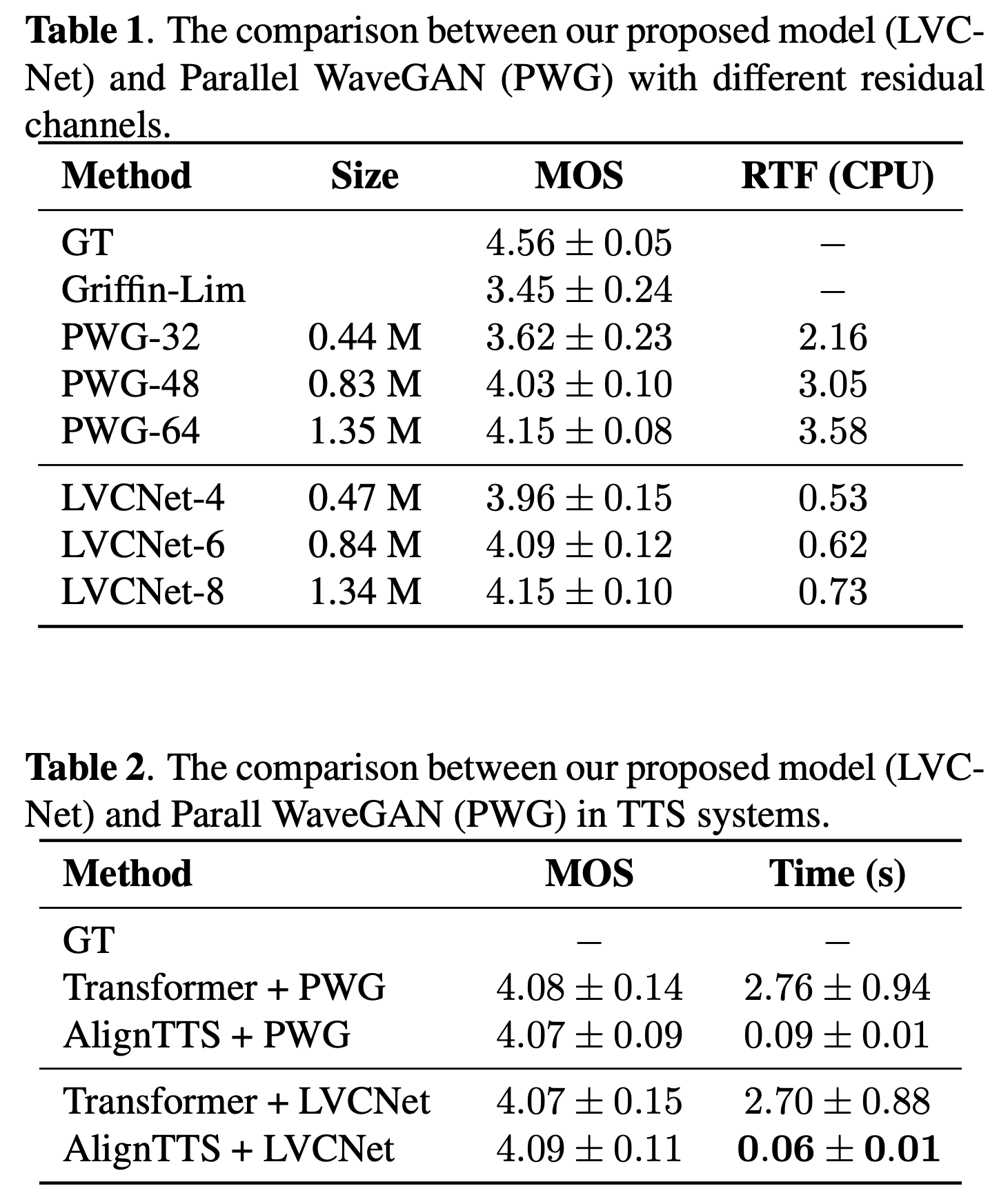 평각 항목으로는 Mean opinion score (MOS) 가 사용되었는데요. Parallel WaveGAN 과 비교했을 때, 매우 유사한 MOS 점수를 받았습니다. 하지만, RTF(CPU) 를 보면 그 연산 속도가 매우 빨라진 것을 확인할 수 있습니다. 즉, 성능 저하 없이 매우 빠르게 작동하는 것을 확인할 수 있습니다.
평각 항목으로는 Mean opinion score (MOS) 가 사용되었는데요. Parallel WaveGAN 과 비교했을 때, 매우 유사한 MOS 점수를 받았습니다. 하지만, RTF(CPU) 를 보면 그 연산 속도가 매우 빨라진 것을 확인할 수 있습니다. 즉, 성능 저하 없이 매우 빠르게 작동하는 것을 확인할 수 있습니다.
나의 의견
소리 데이터는 continous 한 데이터인데, 각 구간 별로 서로 다른 가중치를 가지는 convolution filter 를 사용할 수 있는 방법에 제안되어 매우 흥미롭게 읽었습니다. 그런데 한가지 아쉬운 점은 본 논문에서 Kernel Predictor가 매우 중요한 역할을 하는 데 해당 모듈 구조를 공개하지 않은 것 같아 아쉽습니다.
Reference
LVC 논문 : https://arxiv.org/abs/2102.10815
Github : https://github.com/zceng/LVCNet